Unlocking Scalability by Migrating to Microservices
Author: Zack Garbowitz, Skillz Software Engineer
The Skillz platform hosts over 3.5 million mobile gaming tournaments every day. We’ve been growing rapidly since 2012, and with exponential growth come energizing backend scaling challenges. In 2017, we decided to migrate away from our legacy monolithic application toward a series of microservices to scale both our technology and our people. This blog touches on how we made that decision, as well as lessons learned through the transition.
We built the original Skillz back-end system using Groovy and the Grails web framework, backed by several MySQL databases. We also used RabbitMQ for messaging and Redis as a caching mechanism. Since the Skillz platform manages millions of tournaments daily, many of which include data modifications in multiple tables, we leverage MySQL for online transaction processing. However, MySQL has historically been the largest bottleneck in our system, so we were largely focused on how to optimize its usage as we thought about scaling.
In 2017, Skillz started experiencing massive growth including record-breaking traffic every month. Such rapid growth makes for an exciting engineering experience, but it started exposing thorny bottlenecks in the system. We worked tirelessly the previous two years to improve our legacy Grails system so it would scale more efficiently. However, we started realizing our current trajectory would not be enough to take Skillz to new heights. Ultimately, we decided to undertake the massive project of re-writing our entire backend for multiple reasons:
- Grails: We started with the Grails web framework in 2012 at the time Skillz was founded. Initially this was a good choice because we were able to hit the ground running and pump out a lot of code quickly. However, as we grew, it became clear that our initial framework lacked runtime speed and we needed to uplevel our back-end systems and processes to align with the growing expertise of our teams.
- Groovy: Since we chose the Grails framework, all our code was written in Groovy, which made it easy for the development team to write simple, clean code. However, from a runtime perspective, Groovy impeded system growth at scale.
- Hibernate/GORM: The Grails framework is built on top of hibernate and has its own object-relational mapping (ORM) layer called GORM. The GORM framework makes it easy to define objects and start querying databases in a simple manner. Our codebase was developed relying heavily on GORM, but the framework made it too easy to unintentionally write poor-performing code. We had a few instances where a new developer introduced expensive queries into the system completely by accident. There are also scenarios in which the framework unncessarily issues many database transact and commit statements. After a few speed bumps, we decided the Grails data layer and GORM were not the right fit and slowing us down.
- Lack of caching: In early startup mode, our top priority was building everything as fast as possible to ship a tremendous volume of features quickly. As a result, we did very little caching in our legacy codebase and sent a huge load to MySQL databases. On top of that, due to our code structure and heavy use of GORM, it was difficult to implement caching and engineers spent too much time managing the framework’s implementation details. We saw a huge opportunity to reduce load on our backend databases via more caching.
- Lack of read-replicas: Similar to caching, we used a fairly standard MySQL setup with a single master and several read-replicas for availability. However, we weren’t sending enough read queries to our replicas. Every query in the legacy system went directly to the master. Again, we attempted to add replica datasources and encountered additional GORM-related performance issues that caused us to change our direction. We knew there was a large opportunity to leverage read-replicas, but didn’t feel we could safely make the change in our legacy system.
- Legacy codebase: By 2017, we knew many areas of the code could be more cleanly designed. Services were often much too large, and we had too many shared responsibilities between components. Many parts of the codebase were begging for a rewrite, and we were eager to oblige.
As we worked to overhaul our legacy system, we set our sights on designing a new system to scale with us for the next generation of growth. Our primary objectives were:
- Protecting our backend datastores: Since we could not horizontally scale our database layer, we needed to do everything we could to optimize its usage.
- Separation of concerns: We wanted to break apart our monolithic application so that features would be isolated from one another. That way a failure in one part of the system would not cascade to the rest.
- Allowing the organization to scale: Splitting our monolith into many components would allow more engineering teams to easily own and develop smaller parts of the system.
As a result, we designed a new microservices system based on Java and Spring Boot — Java because our development team was already experienced with JVM technologies and Spring Boot because it is an easy-to-use web framework with strong community support. These frameworks promised substantial performance benefits over Groovy and Grails, satisfying our scaling and reliability requirements by separating concerns and allowing different engineering teams to own different microservices.
The first question we had to answer was: “How should our monolith be divided up?” Since our biggest concern was enabling our databases to scale, we started with our data model, dividing data into groups based on a couple of core factors:
- Functional purpose of the data. Is it used for user management, facilitating tournaments, or processing payments? We wanted to keep groups of logical functionality together in the same service.
- Access pattern of the table. We aimed to group tables with similar usage patterns together, so we could easily tune performance and simplify the responsibilities of any individual service.
Based on these factors, we wound up with nine major groupings of data, and these formed the basis of our new services. On top of that, we created a front-door API Gateway service to perform authentication and basic filtering on all requests before they were passed along to the relevant other services. Our final design looked something like this:
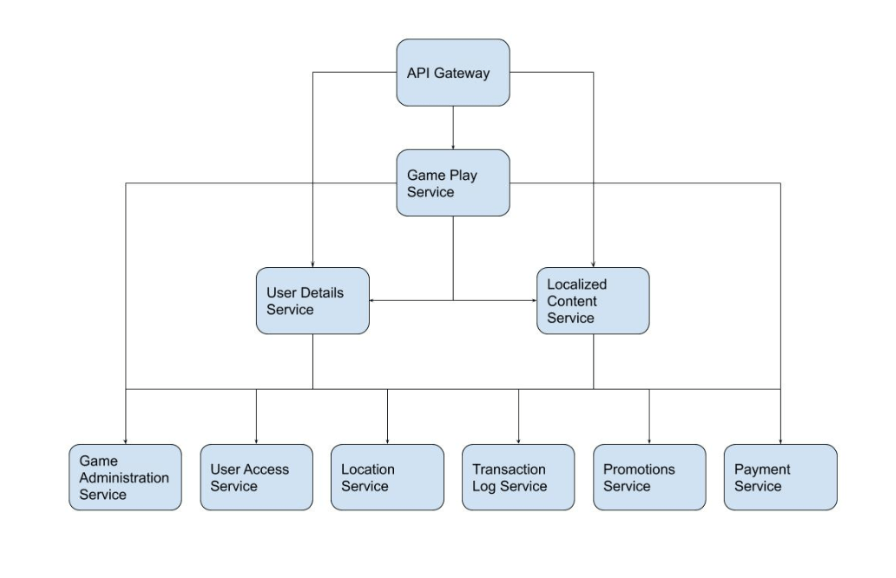
In dividing up data through a combination of purpose and usage patterns, we created logical groups of functionality. A key concept in our new system was data ownership. We wanted to guarantee that only a single service has access to any particular piece of data, so the service could independently determine the most efficient way to store data and better optimize via write-through caches.
We made additional design decisions when developing these new services, including:
- jOOQ ORM Library: Instead of using a hibernate-based ORM solution, we decided on jOOQ because it offers more granular control over how SQL queries are generated and removes the risk of accidentally introducing expensive queries into the system.
- Cache-first mentality: We aggressively cache as much as possible in the new system through a combination of storing data in redis and local caffeine caches. For every piece of logic that is migrated to our new system, we implement caches to reduce load on backend datasources.
- Utilize read replicas: We also moved as many reads as possible away from our master databases and onto read-replicas, allowing us to easily scale reads to keep load off of the master.
Our final consideration in creating the new system was how to manage the migration of our web traffic. Our legacy monolith was already handling millions of tournaments daily, so we needed a strategy to smoothly rollout the newly migrated functionality with minimal interruptions. This felt sort of like trying to change your tires while driving down the highway. The first strategy we considered was to identify a certain class or piece of functionality in the legacy system, migrate it to the microservices, and update our monolith to call out to a new microservice for that functionality. This would allow us to break away logical portions of our system slowly over time. However, this strategy required heavy modifications in our legacy system, and created dependencies between our legacy and new systems.
It was already slow and arduous to develop in our legacy Grails stack. Instead we decided to convert vertical slices of functionality. Rather than identifying a single class and moving it to a microservice, we converted entire endpoints to the new system. We then used our front door Nginx servers to route web traffic to either the legacy or new system, which allowed us to separate the two systems with minimal work on the legacy system. While it required more up-front investment, the long term payoff was well worth it.
With this plan in mind, we embarked on the daunting project of re-writing our codebase in the microservices system. Since then we’ve found massive success with our new framework, and today our microservices handle about 75 percent of our web traffic. Our average API response time improved by 80 to 90 percent through our use of heavy caching combined with the runtime improvements brought on by Java and Spring Boot. Finally, we’ve accomplished our primary goal of protecting our backend databases from excessive load and scaling to handle our rapidly growing user base.
While we’re satisfied with the successes that have come out of building our new system, we’ve also had to navigate obstacles associated with a new, more distributed world:
- Operational overhead: We had a pretty simple build and deploy pipeline scripted in Jenkins that included manual monitoring while deploying our code to production. Moving to microservices meant we suddenly transitioned from managing a single service to more than 10 services overnight. This created more operational overhead for our engineering teams to manage.
- Additional failure points: In a monolith, calls from one java service to another are essentially guaranteed to occur. Shifting to microservices introduced a new layer of challenges in interservice communication. We use a combination of HTTP requests and message passing, which introduces more opportunities for failure.
- Distributed transactions: In our monolith, we opened a single MySQL transaction and felt confidence that our data would be either consistently written or rolled back. In the microservices system, we often have requests that need to change state across several different services consistently. Managing these distributed state changes introduces more complexity, so tasks that were trivially easy in our monolith became very complicated.
- Learning curve: In some ways, it’s more difficult to be a developer in a microservices world. When running and debugging locally, there are many more services to keep track of and ensure are working properly. You may end up juggling many more IDE windows and jumping between projects to find the code you need. A distributed world can complicate simple tasks, requiring more experience and knowledge to confidently develop in our new system.
Despite these challenges, our microservices migration is setting us up for success. We made the transition at the right time in our growth trajectory and our new system is poised to scale with us into the foreseeable future.
Passionate about tackling big scaling challenges? Love working with complex distributed systems, and making them tick? Skillz has an enormous amount of scaling ahead of us, and we want your help! Check out our jobs at skillz.com/careers to learn more.